Google Scholar's broken Recaptcha hurts libraries and their users
Posted on Fri 02 September 2016 in Libraries
Update 2016-11-28: The brilliant folk at UNC figured out how to fix Google Scholar using a pre-scoped search so that, if a search is launched from the library web site, it will automatically associate that search with the library's licensed resources. No EZProxy required!
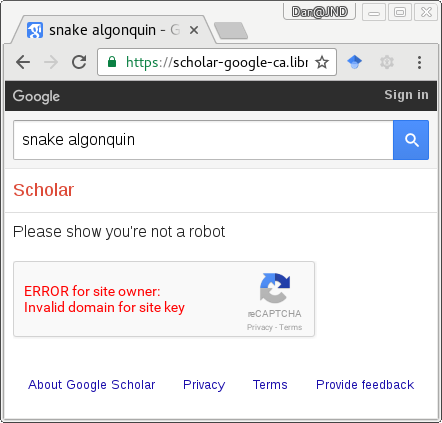
For libraries, proxying user requests is how we provide authenticated access--and some level of anonymized access--to almost all of our licensed resources. Proxying Google Scholar in the past would direct traffic through a campus IP address, which prompted Scholar to automatically include links to the licensed content that we had told it about. It seemed like a win-win situation: we would drive traffic en masse to Google Scholar, while anonymizing our user's individual queries, and enabling them swift access to our library's licensed content as well as all the open access content that Google knows about.
However, in the past few months things changed. Now when Google Scholar detects proxied access it tries to throw up a Recaptcha test--which would be an okay-ish speed bump, except it uses a key for a domain (google.ca of course) which doesn't match the proxied domain and thus dies with a JS exception, preventing any access. That doesn't help our users at all, and it hurts Google too because those users don't get to search and generate anonymized academic search data for them.
Folks on the EZProxy mailing list have tried a few different recipes to try to evade the Recaptcha but that seems doomed to failure.
If we don't proxy these requests, then every user would need to set their preferred library(via the Library Links setting) to include convenient access to all of our licensed content. But that setting can be hard to find, and relies on cookies, so behaviour can be inconsistent as they move from browser to browser (as happens in universities with computer labs and loaner laptops). And then the whole privacy thing is lost.
On the bright side, I think a link like https://scholar.google.ca/scholar_setprefs?instq=Laurentian+University+Get+full+text&inst=15149000113179683052 makes it a tiny bit easier to help users set their preferred library in the unproxied world. So we can include that in our documentation about Google Scholar and get our users a little closer to off-campus functionality.
But I really wish that Google would either fix their Recaptcha API key domain-based authentication so it could handle proxied requests, or recognize that the proxy is part of the same set of campus IP addresses that we've identified as having access to our licensed resources in Library Links and just turn off the Recaptcha altogether.