The wonderful new OpenLibrary Read API and Evergreen integration
Posted on Thu 02 June 2011 in Libraries
Back in early May, I was in San Francisco for Google I/O. I had booked an extra day with the hopes of either doing some site-seeing or meeting up with the OpenLibrary team. After firing off an email to find out if anyone there was interested on working on some tighter integration between OpenLibrary and Evergreen, the answer from George Oates was an enthusiastic "Yes!". So, we spent a beautiful sunny day inside the Internet Archive headquarters discussing possible directions for this integration. Alcatraz, you can wait for my next trip...
As it turned out, the timing was great. I had spent a day hacking on the OpenLibrary "added content" module for Evergreen during the Evergreen hackfest (which I spent in an airport due to an eight-hour fog delay... different story), so I was quite familiar with the existing OpenLibrary Book API and their patterns of use were fresh in my brain. The biggest problem with the existing Book API, from my perspective, was that I had to make two calls for each work that I was interested in retrieving information about; one call returned the data (stable elements) and one call returned the details (unstable, but quite interesting elements like the table of contents, excerpts, etc).
The OpenLibrary team had this in their sights as well - but they wanted to tackle a bigger target. Rather than making one or more calls per work, they wanted to expose an API that would let users request info for multiple works in one shot: the Shotgun API (known amongst more polite company as the Read API). Loosely modelled on the Hathitrust API, it would also focus on exposing URLs for reading or borrowing (using the relatively recent OpenLibrary borrowing program) exact matches or similar editions. It sounded great, and we spent the afternoon fleshing out how we wanted it to look and work. My role was largely that of the third-party developer - the API customer - and we had great discussions.
Working code wins
Of course, discussions are one thing, and working code is another. OpenLibrary developer Mike McCabe was riding shotgun on the development of the Read API, and once he had enough working code in place, he contacted me to ask me to start developing against it. It was the usual development process: I started with a hard-coded sample JSON output, then as Mike pushed more functionality into a server environment I was able to test and expand my client-side code.
So where are we now? I can vouch that working with the all-in-one Read API, as a developer, is sweet. All of the data elements are readily visible in sweet, sweet JSON, in a single call, and it is utterly simple to pull the bits that you want to expose. I had been trying to pull together ebook links and the like from the Books API, and the use of the items list makes that absolutely painless for developers. Kudos!
Evergreen has a largely rewritten OpenLibrary added content module built against the Read API sitting in the Evergreen working repository user/dbs/openlibrary-read-api branch. As the Borrow and Read functions depend on IP address range matching, I have added the ability to proxy the Read API requests via the Evergreen server - so that if an Evergreen institution has special access rights to the OpenLibrary collection, their patrons will see the appropriate levels of access in the catalogue. Oh yes, the catalogue; as we were already using OpenLibrary by default for cover art, tables of content, and excerpts in Evergreen since the 2.0 release, the major difference that will be visible to Evergreen users will be in search results:
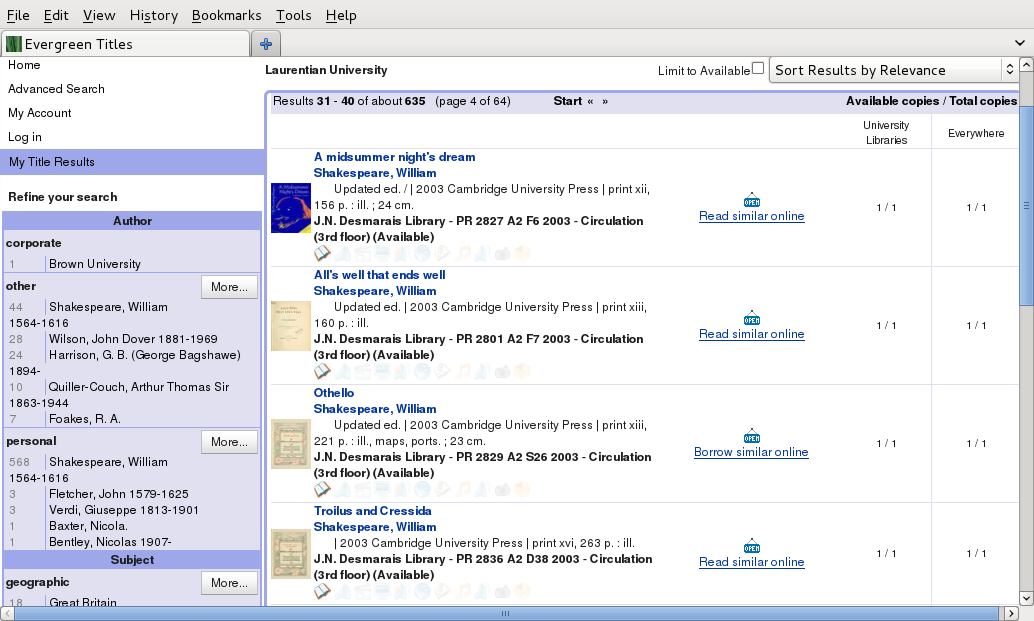
As you can see, if you have left the OpenLibraryLinks variable turned on in the result_common.js file, Evergreen will search for a matching record in OpenLibrary and tell you if an online version is available. It tells you whether the online version is an exact match, or similar, and will also expose items that you can borrow from OpenLibrary. Given the preponderance of print materials that still remains in our collections, and our users' general preference for anything electronic, I think this will be an extremely popular feature.
Moving forward
There are a number of areas that could use more polish and tender loving care.
First and foremost, OpenLibrary supports matching based on ISBNs, LCCNs, OCLC numbers, and OpenLibrary IDs; right now, the Evergreen support is based strictly on ISBNs, which of course don't exist for many of the older materials in our collections. So a fruitful direction would be to take the regular dump of data that OpenLibrary thoughtfully provides (yay for open data) and use that to augment our records to include OpenLibrary ID numbers to use as a match point.
There is the small matter of merging these changes back into Evergreen proper.
I developed against the Evergreen 2.0 branch because I wanted to be able to put this code into production as soon as possible, so there will be a tiny bit of merging pain to get this into master and backported properly. However, the changes are quite localized and should be agreeable, so hopefully this will not sit in a branch for too long.
At this early stage in the Read API's release, I have also found that it can be a bit slow to respond to requests containing a number of identifiers (or perhaps a large number of records and items). It is to be expected that functionality comes first and optimization comes later, so I have great hopes for improved performance once the Read API settles down.
Of course, once you have the Read API, you need an Write API - and I hope to be able to help pilot that as well, because the potential communal benefit of a Write API for library systems that have integrated with OpenLibrary is huge. Imagine a system where, when you ask for added content based on a given identifier, if the system says "Huh, I don't know anything about that identifier" it follows up with "Hey, can you POST what you know about it to this URL?".
OpenLibrary could then run its algorithms and either add an edition to an existing work or generate a new work. We should also be able to expose OpenLibrary's metadata editing tools for our users, so they can flag bad cover art, or add a table of contents to works that they are passionate about, or post a favourite excerpt... Enabling a bi-directional give and take between systems has the potential to quickly make OpenLibrary a huge knowledgebase of open data. It would be a great boon for libraries, and I hope we can make it happen.
Update 2011-06-02 21:54 EDT: The omission of Mike McCabe's name has been corrected. Also, I forgot to thank my employer, Laurentian University, and the University of Windsor for allowing me to invest some of my time on strengthening Evergreen's ties to OpenLibrary. I believe this is the beginning of a solid, mutually beneficial partnership!