A Flask of full-text search in PostgreSQL
Posted on Sun 11 August 2013 in Python
Update: More conventional versions of the slides are available from Google Docs or in on Speakerdeck (PDF)
.
On August 10, 2013, I gave the following talk at the PyCon Canada 2013 conference:


I’m a systems librarian at Laurentian University.
For the past six years, my day job and research have enabled me to contribute pretty heavily to Evergreen, an open source library system written largely in Perl and built on PostgreSQL.
But when I have the opportunity to create a project from scratch, for work or play, Python is my go-to language.

I promised to provide an example of a full-text search engine built with Flask and PostgreSQL written in under 200 lines of code; you can find that at either Gitorious or Github.

Last summer, the Laurentian University Library digitized 50 years of student newspapers - over 1,000 issues.
We posted them all to the Internet Archive and got OCR’d text as a result.
But finding things within a particular collection on the Internet Archive can be difficult for most people, so we felt the need to create a local search solution.

We were already using PostgreSQL to track all of the individual issues, with attributes like newspaper name, volume, edition, publication date.
This gave us the ability to filter through the issues by year and issue number, which was a good start. But we also wanted to be able to search the full text for strings like “Pierre Trudeau” or “Mike Harris”.
A common approach is to feed the data into a dedicated search engine like Solr or Sphinx, and build a search interface on top of that.
But PostgreSQL has featured full-text search support since the 8.3 release in 2008. So I opted to keep the moving parts to a minimum and reuse my existing database as my search platform.

Our example table contains a “doc” column of type TEXT; that’s where we store the text that we want to search and display. We also have a “tsv” column of type TSVECTOR to store the normalized text.
The TSVECTOR column is typically maintained by a trigger that fires whenever the corresponding row is created or updated. So... you just insert TEXT into the doc column, and the trigger maintains the tsv column for you.
PostgreSQL includes the tsvector_update_trigger() for your convenience, as well as a trigger that uses different language-oriented normalizations based on the value of a specified column. Naturally, you can define your own trigger that invokes the to_tsvector() function.
To provide good performance, as with any relational table, you need to define appropriate indexes. In the case of full-text search, you want to define a GIN (or GiST) index on the TSVECTOR column.
Note: GIN indexes take longer to build, but provide faster lookup than GiST.
Finally, we INSERT the text documents into the database. The ID and TSVECTOR columns are automatically generated for us.

Each text document is:
- Parsed into tokens (words, white space, URIs, file paths)
- Each token is then normalized with one or more dictionaries (word tokens may get stemming and stop words; URIs might have “www.” stripped; everything gets folded to lower case)
- Et voila: the text-search vector for our text document has been created!
PostgreSQL bundles a number of language-specific dictionaries to support different stemming algorithms and default sets of stopwords.
In this example, we can see that PostgreSQL has stemmed “sketching” to remove the verb suffix, removed “the” altogether as a stop word, and stemmed “trees” to its singular form.
You can also see that the TSVECTOR stores the position where each token occurs, to support relevancy ranking algorithms that boost the relevancy of terms that are located closely together.

But it's a doozy of a query!
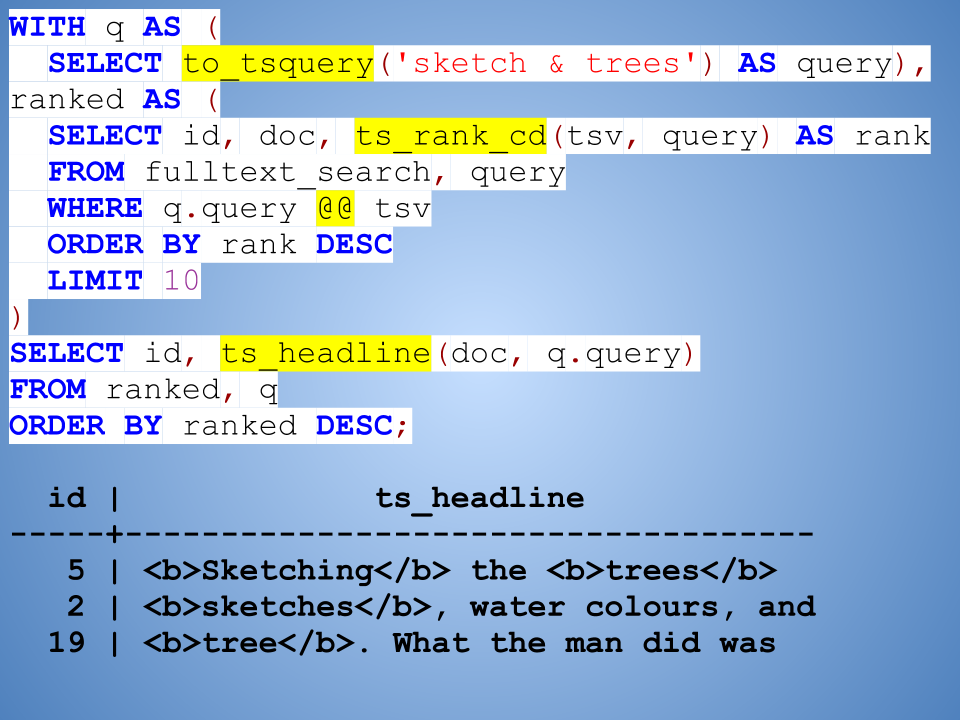
Yes, there is a lot going on here.
First, this is just a regular SQL statement that happens to use the WITH clause to define named subqueries (“q” and “ranked”).
The to_tsquery() function takes an incoming full-text search query and converts that into a parsed, normalized query.
The ts_rank_cd() function compares the TS_VECTOR column against the query to determine its relevancy score.
We need to restrict it to rows that match our query, so we use the @@ operator (PostgreSQL allows data-type specific operators like this) and then take the top ten.
*Note*: the query, limit, and offset are hardcoded here for illustrative purposes, but in the actual application these are supplied as parameters to the prepared SQL statement.
Finally, we use the ts_headline() function to give us a highlighted snippet of the results.
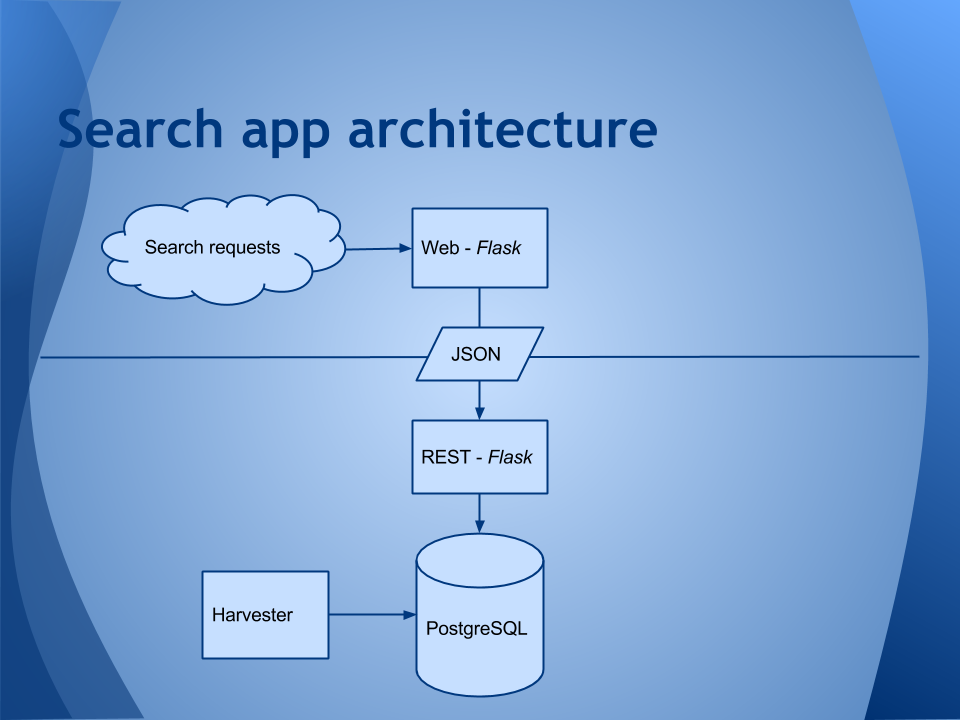
The harvester is a Python 3 application that uses the ‘postgresql’ module to connect to the database.
The REST and Web applications in the IA Harvester application are Python 2, largely because they use Flask (which iswas Python 2 only). But in the demo application, I’ve converted them to Python 3.
While I could have simply written the Web and REST applications as a single Flask Web app that talks directly to the database, I opted to couple them via a JSON interface for a few reasons:
- Decoupling the web front end from the search back end means that I can augment or swap out either piece entirely without affecting the overall experience.
- If performance becomes an issue, I could add caching where profiling warrants it.
- If the service ends up being incredibly popular and PostgreSQL turns into a bottleneck, even with caching, I could set up a Solr or Sphinx instance instead.
I can change from Flask to another Web application framework on either piece.
I can separate the hosts if I need to throw more hardware at the service, and/or virtualize it on something like Google App Engine.

With so many Python web frameworks available, why Flask?
- Routes as decorators was admittedly the biggest draw, simplifying routing enormously!
- Solid Unicode support was a must as well, as our newspapers are bilingual (English / French).
At the time I opted to try out Flask, the project’s public stance towards Python 3 was not warm. However, with the 0.10 release in June 2013, all that has (thankfully!) changed; Python 3.3 is supported.

Flexible format:
- query: gives us the original query so we can echo that back to the user
- results: is a list of the highlighted snippets that we returned from our full-text search
- years: a facet that for the years in which hits were found, including the number of hits per year
- collections: a facet for the collections in which hits were found, including the number of hits per collection
- meta:
- total: the total number of hits
- page: the page we’re on
- limit: the number of hits per page
- results: the number of hits on this page of results

We’ve already seen the decorator-route pattern before, and of course we need to quote, encode, and decode our search URL and results.
The Flask-specific parts are helper methods for getting GET params from the query string, and rendering the template (in this case, via Jinja2), by passing in values for the template placeholders.


At this point, the UI is functional but spartan. I’m a database / code guy, not a designer. Luckily, I have a student working on improving the front end (hi Emily!)
Further information:
Demonstration application:
Internet Archive harvester project: https://gitorious.org/ia-harvester
PostgreSQL full-text search: